
PDF OCR and Named Entity Recognition: Whistleblower Complaint - President Trump and President Zelensky

In this short post we are going to retrieve all the entities in the “whistleblower complaint regarding President Trump’s communications with Ukrainian President Volodymyr Zelensky” that was unclassified and made public today.
I apply the techniques in my two previous blog posts, that is PDF OCR and named entity recognition. Instead of reading through the 16 pages to extract the names, dates, and organizations mentioned in the complaint, we will use natural language processing as a tool to automate this task .
If any of the techniques we are using is not familiar to you, refer to my blog posts Creating a Searchable Database with Text Extracted from Scanned Pdfs or Images and Named Entity Recognition With Spacy Python Package.
The PDF we are using is published on Washington Post. You can download and save to your directory but for this project, I decided to make every bit of the process automated. I used urllib python package to download the pdf. The entire code can be found on my GitHub page.
We import all the needed python packages.
from PIL import Image
import pytesseract
import pandas as pd
import io
from wand.image import Image as wi
pd.set_option('max_colwidth', 2000)
pd.options.display.max_rows = 500
import pandas as pd
#First install tesseract-ocr from this link https://github.com/UB-Mannheim/tesseract/wiki
#Then add this line for tesseract ocr to work
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe"
Downloading the PDF from Washington Post using urllib instead of manual download.
from urllib.request import Request, urlopen
import requests
url="https://games-cdn.washingtonpost.com/notes/prod/default/documents/3b5487de-f987-4cef-b59b-c29bb67687ac/note/ef3465c1-465b-4e68-9b36-08b5946b0df4.pdf#page=1"
import urllib.request
req = urllib.request.Request(url, headers={'User-Agent': 'Mozilla/5.0'})
r = requests.get(url)
with open("trump_ukrain.pdf", "wb") as code:
code.write(r.content)
PDF OCR
These few lines of code import the pdf we downloaded, convert the file to images and then extract the text in the images. The resolution you set has an effect on the performance of the code. Higher resolution is better but makes the code slow.
pdf = wi(filename = "trump_ukrain.pdf", resolution = 300)
pdfImg = pdf.convert('jpeg')
imgBlobs = []
for img in pdfImg.sequence:
page = wi(image = img)
imgBlobs.append(page.make_blob('jpeg'))
extracted_text = []
for imgBlob in imgBlobs:
im = Image.open(io.BytesIO(imgBlob))
text = pytesseract.image_to_string(im, lang = 'eng')
extracted_text.append(text)
print('Done extracting text')
Save the extracted text to a dataframe and print the text.
df = pd.DataFrame(extracted_text,columns =['Page_Text'])\
.replace(r'\n',' ', regex=True)
df
Named Entity Recognition.
Import spacy to extract the data from the text file and also set options.
import spacy
import pandas as pd
pd.set_option('max_colwidth', 2000)
pd.options.display.max_rows = 500
These few lines of code loads the spacy large english core language model, loads and parse the text file we are trying to analyse and assign to spacy object named doc. We also take a look at the content of the document loaded.
nlp = spacy.load('en_core_web_lg')
doc = nlp(df['Page_Text'].to_string())
doc
We use a for loop to extract the words, their entities as determined by spacy and the description of each of the entities and put them into a list called table. We will show only the date, organizations, persons, time and work_of_art. See how spacy think “The Honorable Adam Schiff” is a piece of art. NLP is not hundred percent perfect yet.
# Get the entities, labels and explaination to the labels
table = []
for ent in doc.ents:
table.append([ent.text,ent.label_,spacy.explain(ent.label_)])
# Creat a dataframe from the list created above
df2 = pd.DataFrame(table, columns=['Entity', 'Label','Label_Description']).sort_values(by=['Label'])
print(df2.shape)
#filter for Date, org, person, time and work_of_art and dedupe
df3= df2[df2['Label'].isin(['DATE','ORG','PERSON','TIME','WORK_OF_ART'])]
print(df3.shape)
df4=df3.drop_duplicates(subset=None, keep='first',inplace= False)
print(df4.shape)
df4
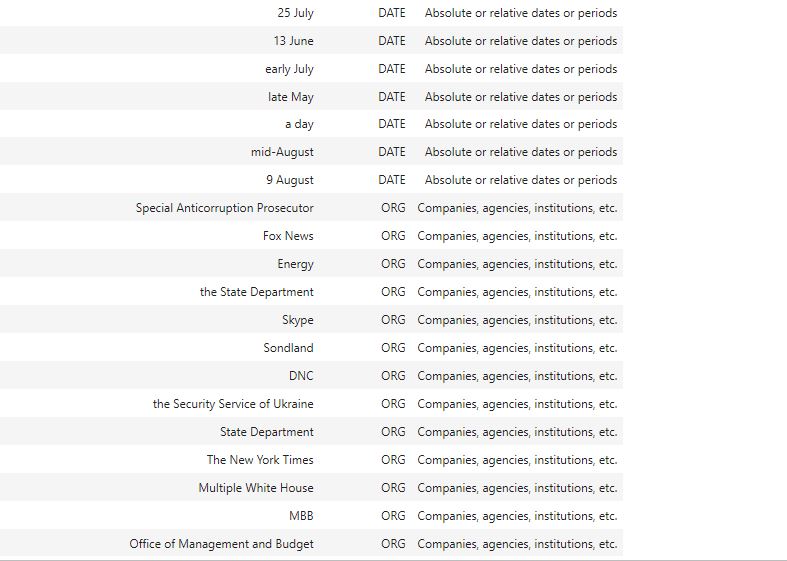
Spacy also gives additional methods to describe or explain what the labels represent. And if you so desire, you can also visualize the entities in the text document.

I welcome feedback and discussion. I can be reached on Twitter @opalbert.