
Exploring the Causes of Death of Soccer Players SPARQL and Python Tutorial

As we watch soccer players exhibit their skills on the pitch at the world cup stage, we would think these players are healthy in all sense, given the amount of work they put in before and during each game. Health experts advise, exercising is paramount for avoiding many diseases. In that context, I wondered what is the impact of exercise on sports men and women, and in particular, soccer players.
These questions cannot be answered for players currently playing in the game because I do not have access to their medical records so I decided to use a public data on Wikipedia which show the causes of death of soccer players on earth.
I decided to make this more of a tutorial so I will share steps of the data acquisition through to the analysis. I wanted to find out the average age at death, and the causes of death of soccer players that have passed away.
Load the required python packages
#%reload_ext signature
# To sign my name at the end of code .You need to have a script saved before it works. You can remove it.
%matplotlib inline
import requests
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import io
chartinfo = ‘Author: Albert Opoku• Data source: wikidata.org’
infosize = 12
Querying data from Wikipedia using SPARQL language
SPARQL developed by W3C is an RDF query language, that is, a semantic query language for databases, able to retrieve and manipulate data stored in Resource Description Framework (RDF) format. I decided to write my SPARQL code in python because python with pandas gives me the ability do my analysis without changing to another programming language.
I will query the following information: Name, Country of citizenship, Cause of death, date of birth and date of death for each soccer player reported dead on Wikipedia.
I would like to acknowledge Ramiro Gómez for sharing his SPARQL python code on GitHub.
query = ‘’’PREFIX wikibase: <http://wikiba.se/ontology#>
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?name ?cause ?dob ?dod ?country WHERE {
?pid wdt:P106 wd:Q937857 .
?pid wdt:P509 ?cid .
?pid wdt:P569 ?dob .
?pid wdt:P570 ?dod .
?pid wdt:P27 ?cot.
OPTIONAL {
?pid rdfs:label ?name filter (lang(?name) = “en”) .
}
OPTIONAL {
?cid rdfs:label ?cause filter (lang(?cause) = “en”) .
}
OPTIONAL {
?cot rdfs:label ?country filter (lang(?country) = “en”) .
}
}’’’
url = ‘https://query.wikidata.org/bigdata/namespace/wdq/sparql'
data = requests.get(url, params={‘query’: query, ‘format’: ‘json’}).json()
I will use the code below to parse the values we need out of the json and save in a pandas DataFrame for analysis. There are 1,390 soccer players reported dead on Wikipedia at the time of writing.
soccer = []
for item in data['results']['bindings']:
try:
soccer.append({
'name': item['name']['value'],
'country': item['country']['value'],
'cause_of_death': item['cause']['value'],
'date_of_birth': item['dob']['value'],
'date_of_death': item['dod']['value']})
except KeyError:
pass
df = pd.DataFrame(soccer)
print(len(df))
df.head()
Let us use df.info() to check the data types and also find out if there are missing values in any of the columns. We will also use the df.describe() to get the summary statistics on the data. Turns out the fields are all object type and there are no missing values.
df.info()
df.describe()
Let us extract the year out of the date of birth and date of death fields so that we can calculate the age of each player.
df[‘date_of_death’] = df.date_of_death.str.slice(0, 4).astype(int)
df[‘date_of_birth’] = df.date_of_birth.str.slice(0, 4).astype(int)
df['age']=df.date_of_death - df.date_of_birth
print(df.head())
df.describe()
It does look like Jackie Benyon was born in the year 2000 but died in 1937. How could that be? That is what you deal with when you work with raw data. We will exclude Jackie Benyon from the data soon. Data on Xie Hui also doesn’t seem to be correct.
df[(df['date_of_death']==426)|(df['age']==-63)]
df=df[df['age']!=-63]
df=df[df['date_of_death']!=426]
df.describe()
After excluding these two players, the average age at death for soccer players is 55.
Now let us visualize the causes of death for the players. I will visualize the top 20 causes. It is worth to note that Wikipedia sometimes publish multiple cause of death for an individual. It could be that doctors attribute multiple diseases as the cause of death for some patients.
title = 'Association Football(Soccer) players top 20 Causes of Death According to Wikipedia'
footer = chartinfo
df['cause of death'] = df['cause_of_death'].apply(lambda x: x.capitalize())
s = df.groupby('cause_of_death').agg('count')['name'].sort_values().tail(20)
ax = s.plot(kind='barh', figsize=(9, 8), title=title,color='xkcd:sky blue')
ax.yaxis.set_label_text('')
ax.xaxis.set_label_text('Cause of death count')
ax.annotate(footer, xy=(-0.1, -0.14), xycoords='axes fraction', fontsize=infosize)
plt.savefig('img',dpi=300, bbox_inches = "tight")
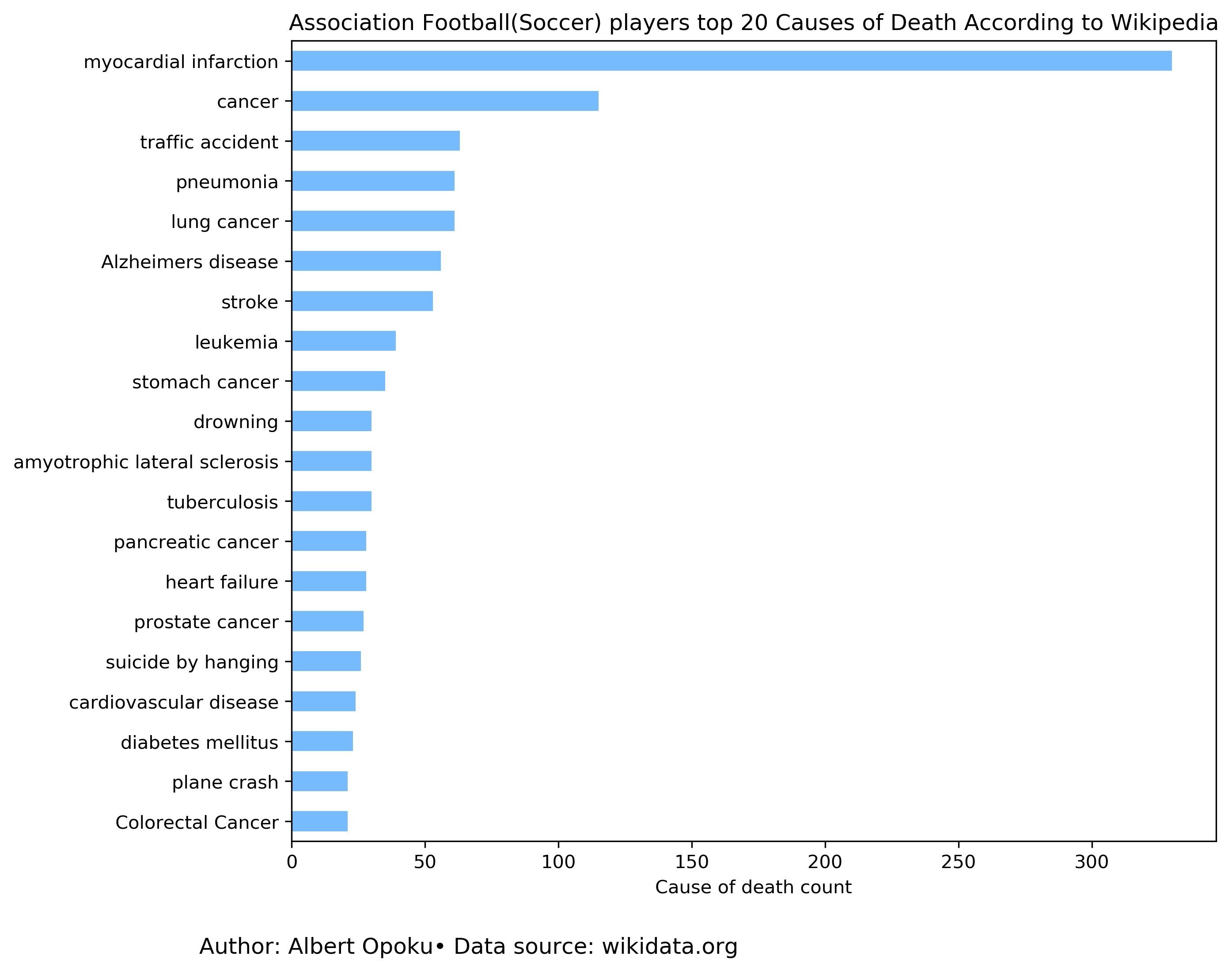
The result is not as expected. You would think people that workout that much won’t develop myocardial infarction aka “heart attack”. Perhaps they stop exercising when they retired from active football or food choices may be blamed. The doctors can help us out. Traffic accident at position number three is interesting. I can’t think about any reason behind this, there surely maybe something going on with these players that is not captured in this data. Have fun, explore the rest of the graph. You can also try your hands on the code. I have saved it on my GitHub
I welcome feedback and discussion. I can be reached on Twitter @opalbert.