
- Following are a collection of data science projects I’ve completed over the past several years
- Kaggle Notebooks can be run in the browser with no downloads required. GitHub notebooks are also provided
- Feel free to get in touch about any of the projects. I’m always willing to discuss data science!
Automated vs Manual Feature Engineering for Machine Learning
| Time | Features | Performance |
|---|---|---|
 |
 |
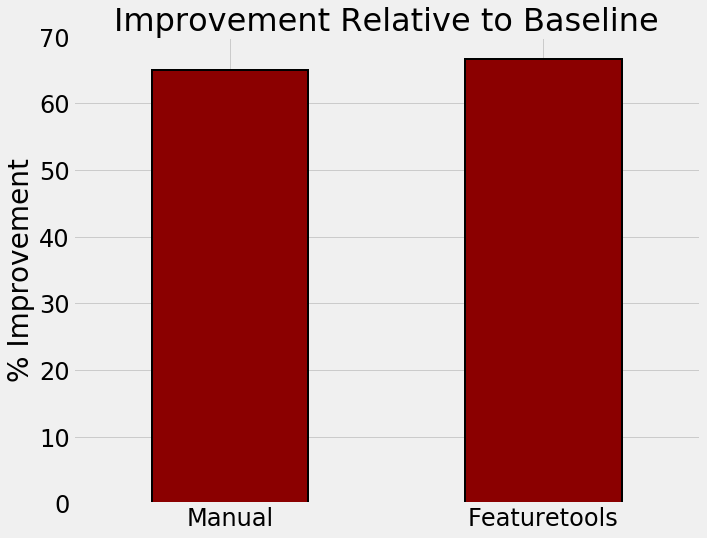 |
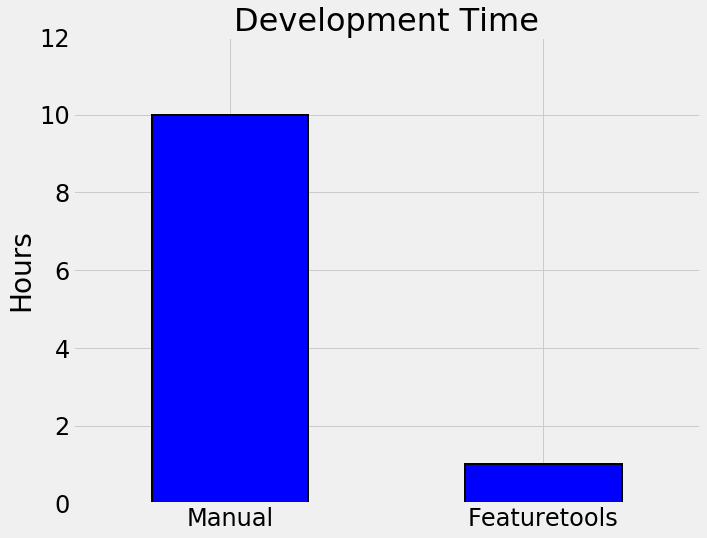
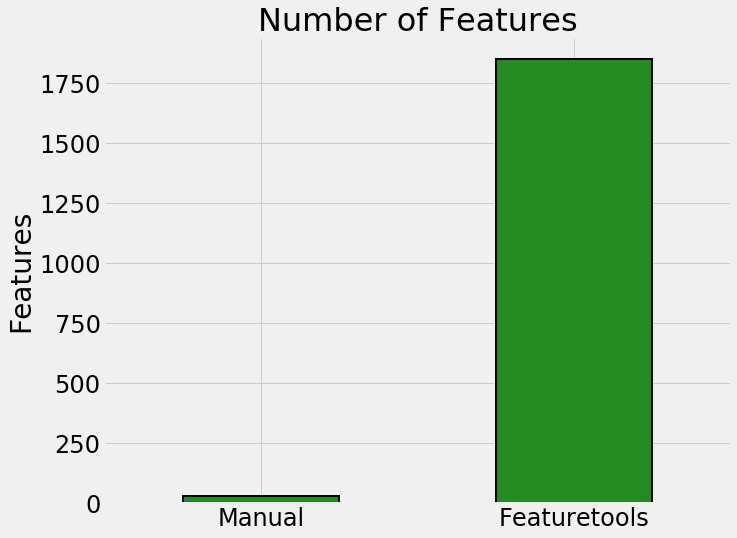
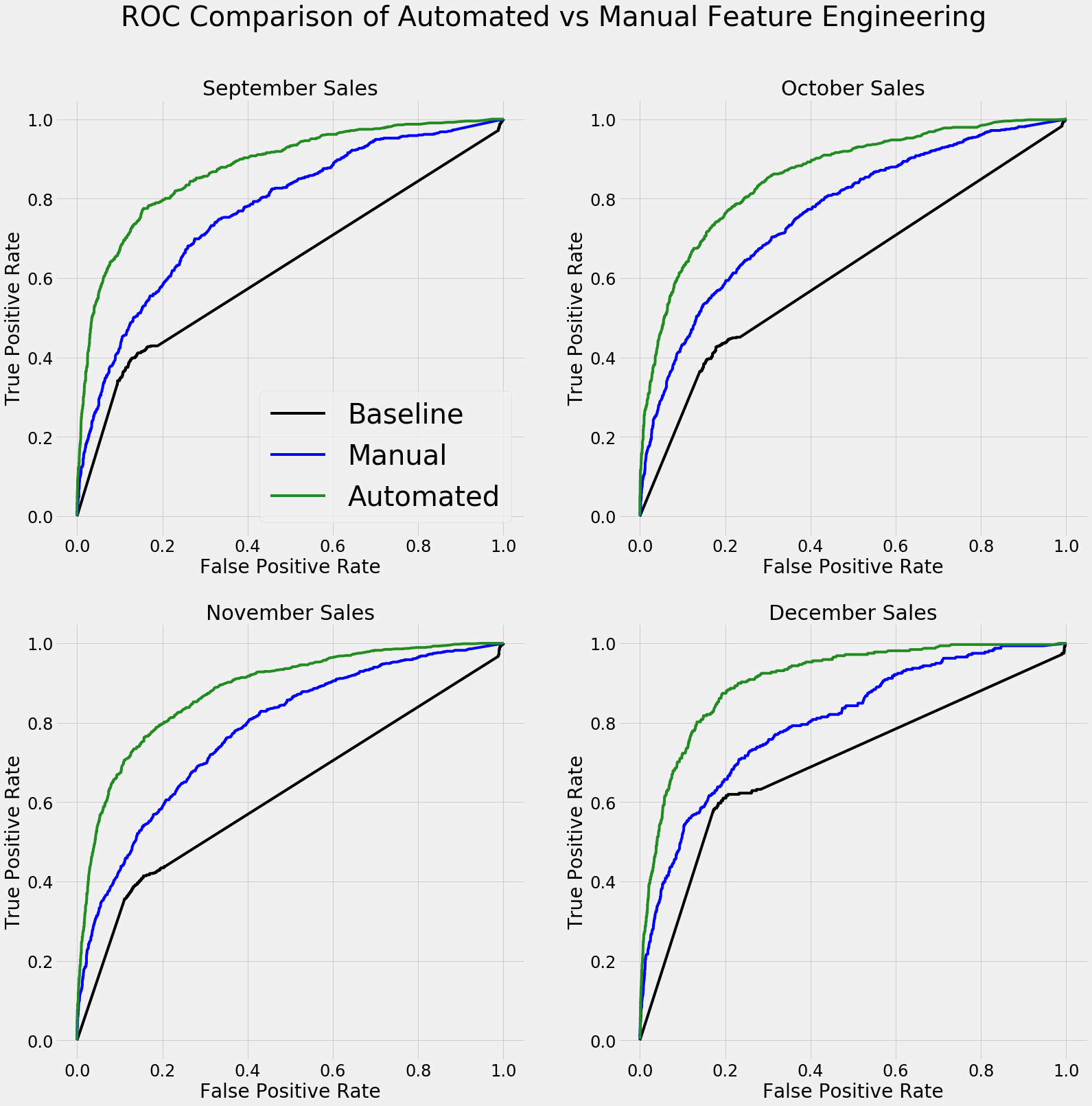
In this project, I took on three different machine learning problems, solving each one with both manual and automated feature engineering using Featuretools. Each of the three projects represents a complete machine learning problem and shows that automated feature engineering can reduce development time by up to 10x, deliver better modeling performance, build explainable features, and prevent data leakage in time-dependent problems. Moreover, automated feature engineering can be applied across datasets using the exact same framework, leading to reliable and efficient feature engineering.
Techniques / Tags
- Feature Engineering
- Machine Learning
- Automation
- Featuretools
Jupyter Notebooks
Article
Data Science for Good: Costa Rica Poverty Prediction
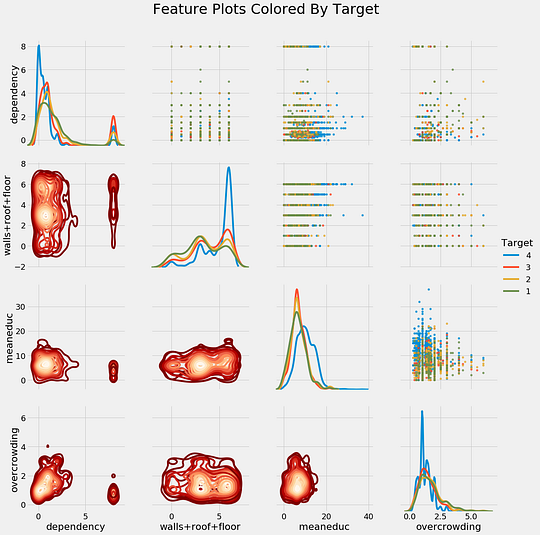 Pairsplot of Features
Pairsplot of Features
Summary
In this complete data science for good machine learning project, I build a gradient boosting machine model to predict poverty levels in Costa Rica. I also experiment with several different methods including UMAP for dimensionality reduction, oversampling to deal with imbalanced classes, recursive feature elimination for feature selection, and automated feature engineering using Featuretools. It turns out the same techniques and skills that can be used to get people to click on more ads can also be used to improve outcomes for our fellow humans.
Techniques / Tags
- Machine learning
- Data science for good
- Python
- Tutorial / walkthrough
- Gradient Boosting Machine
Jupyter Notebooks
- Complete Walkthrough on Kaggle
- Automated Feature Engineering on Kaggle
- Bayesian Optimization on Kaggle
- Oversampling on Kaggle
- Complete Walkthough on GitHub
- Automated Feature Engineering on GitHub
- Bayesian Optimization on GitHub
- Oversampling on GitHub
Articles
- A Data Science for Good Machine Learning Project Walk-Through in Python: Part One
- A Data Science for Good Machine Learning Project Walk-Through in Python: Part Two
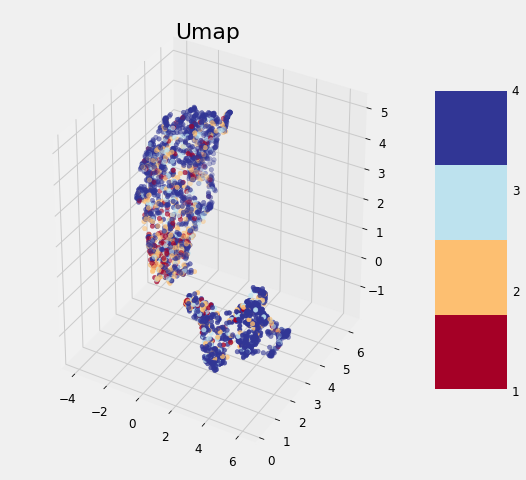 UMAP Embedding of Data
UMAP Embedding of Data
Parallelizing Feature Engineering
| Task Stream | Profile |
|---|---|
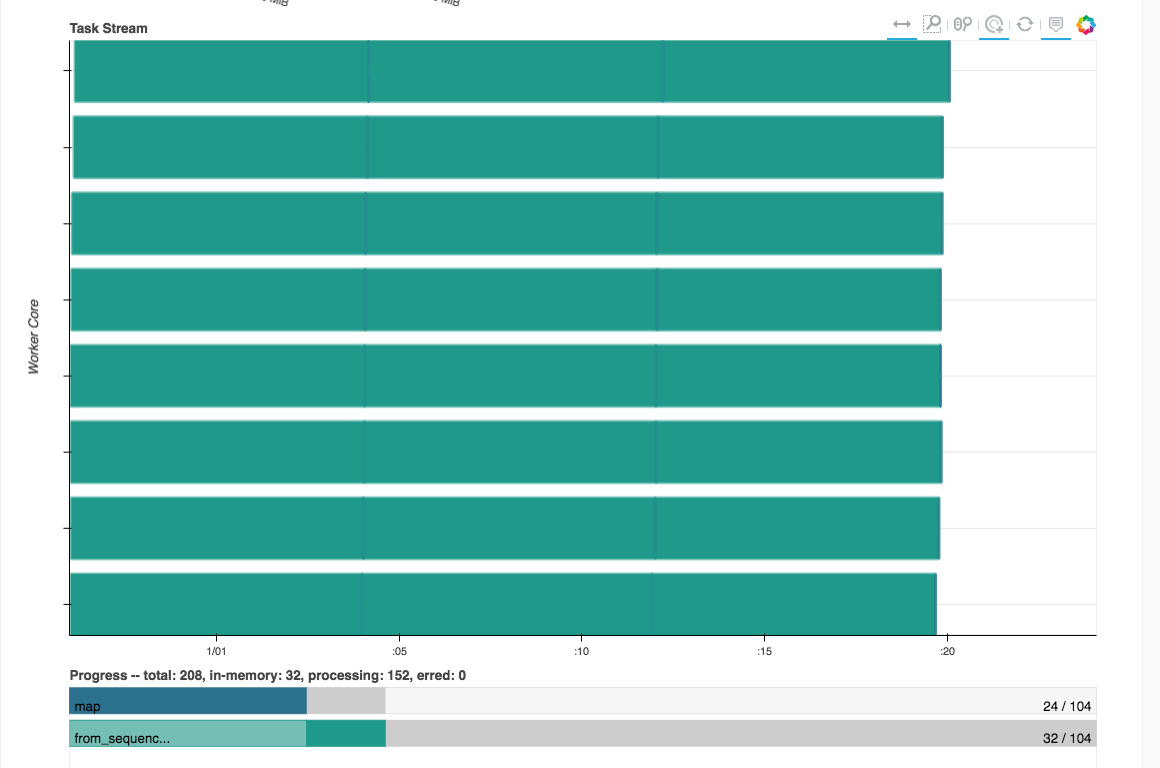 |
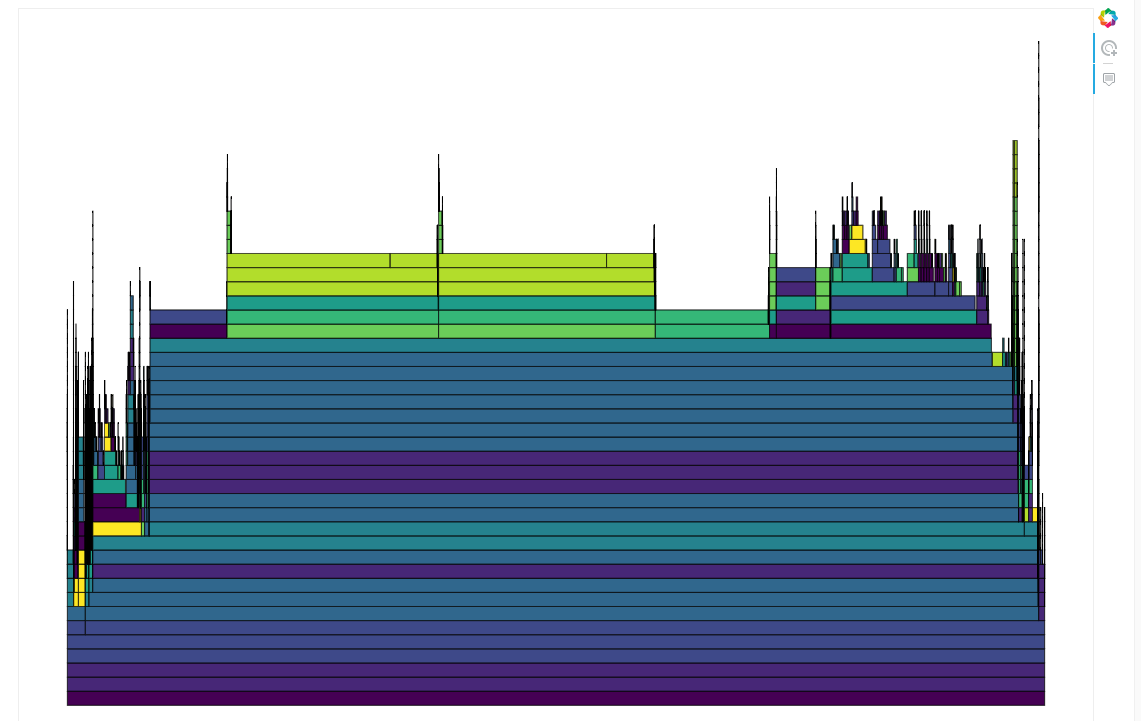 |
Summary
In this project, I use the parallel computing library Dask in order to parallelize a computation-heavy automated feature engineering task, in the process, reducing the run time from over 25 hours to less than 3. Rather than immediately try to get a bigger machine, this project shows how parallel processing allows us to get the most from our available hardware.
Techniques / Tags
- Parallel computing
- Feature Engineering
- Dask
- Python
Jupyter Notebook
Article
A Machine Learning Walkthrough and a Challenge
| Pickups | Dropoffs |
|---|---|
 |
 |
Summary
In this machine learning walkthrough, I build a model to predict the fare of taxi rides in NYC. I also leave readers with a challenge - better my model - as well as several recommendations for building an improved solution.
Techniques / Tags
- Machine Learning
- Python
- Tutorial / walkthrough
- Random Forest